
GBM(Gradient Boosting Machine)
- 부스팅 알고리즘은 여러 개의 약한 학습기를 순차적으로 학습-예측하면서 잘못 예측한 데이터에 가중치를 부여하고 오류를 개선해 나가면서 학습하는 방식
- 대표적으로 AdaBoost와 GBM이 있음
AdaBoost 에이다부스트
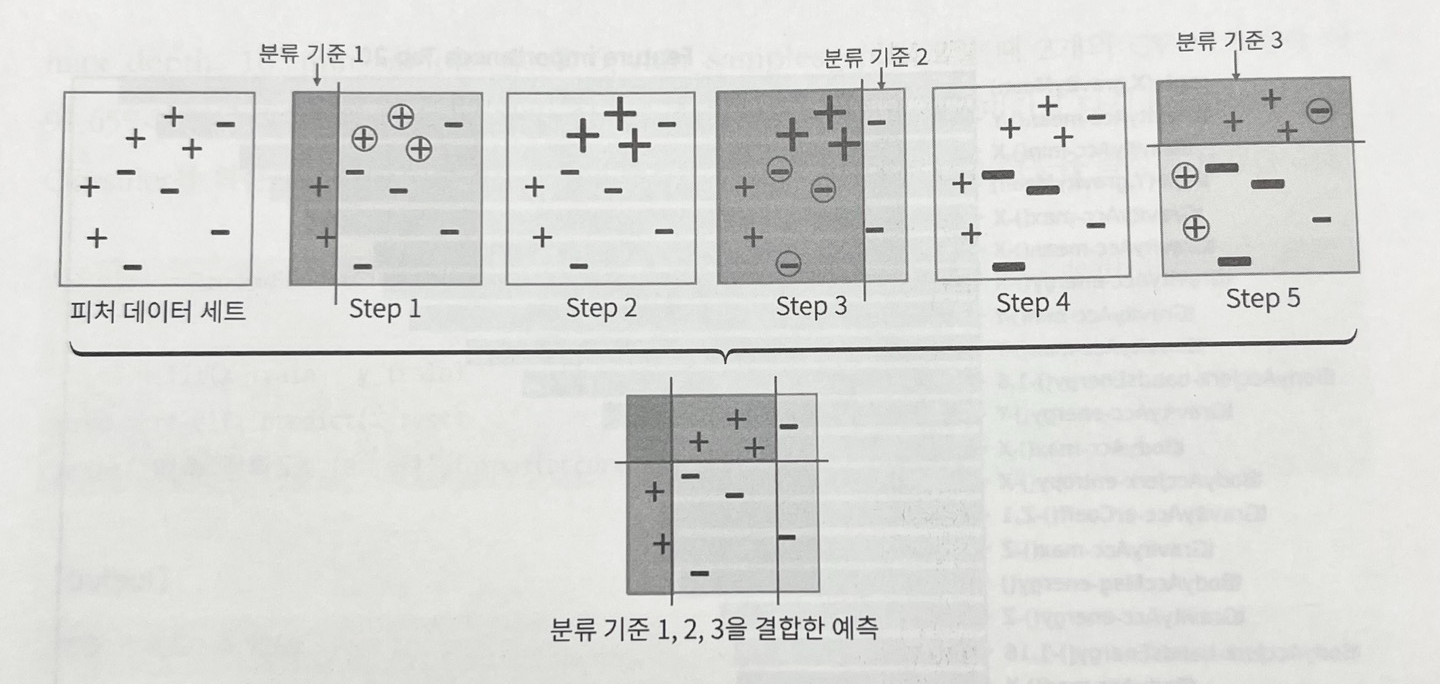
- 맨 왼쪽과 같이 +와 -로 된 피처 데이터셋이 있다면
- step1은 첫 번째 약한 학습기가 분류 기준1으로 +와 -를 분류한 것, 동그라미+가 잘못 분류된 애들
- step2에서 이 오류데이터에 가중치값 부여(0.3), 크기가 커진 +
- step3에서 두 번째 약한 학습기가 분류 기준2로 +와 -를 분류, 동그라미-는 잘못 분류된 애들
- step4에서 이 오류데이터에 더 큰 가중치 부여(0.5), 크기가 커진 -
- step5에서 세 번째 약한 학습기가 분류 기준3으로 +와 -를 분류, 오류데이터 찾음
- 이렇게 순차적으로 오류값에 대해 가중치를 부여한(0.8) 예측 결정 기준을 모두 결합함
- 마지막으로 1,2,3번째 약한 학습기를 모두 결합한 결과 예측임. 개별 학습기보다 정확도가 높아짐
GBM
- AdaBoost와 유사하나, 가중치 업데이트를 '경사하강법'으로 함
- 경사하강법:실제값을 y, 피처를 x1, x2, ..., xn, 피처에 기반한 예측함수를 F(x)라고 하자
- 오류식 h(x) = y - F(x) 을 최소화하는 방향성을 가지고 반복적으로 가중치값을 업데이트하는 방식
- 오류값 = 실제값 - 예측값
- 사이킷런은 GradientBoostingClassifier() 제공
- GBM은 과적합에 강하고 뛰어난 예측 성능을 가진 알고리즘이지만 수행 시간이 오래 걸리는 단점이 있음
GBM을 이용해 사용자 행동 데이터셋을 예측 분류해보자
- 학습시간이 얼마나 걸리는지도 측정
In [ ]:
import pandas as pd
feature_name_df = pd.read_csv('/content/features.txt', sep='\s+', header=None, names=['column_index', 'column_name'] )
In [ ]:
def get_new_feature_name_df(old_feature_name_df):
feature_dup_df = pd.DataFrame(data=old_feature_name_df.groupby('column_name').cumcount(), columns=['dup_cnt'])
feature_dup_df = feature_dup_df.reset_index()
new_feature_name_df = pd.merge(old_feature_name_df.reset_index(), feature_dup_df, how='outer')
new_feature_name_df['column_name'] = new_feature_name_df[['column_name', 'dup_cnt']].apply(lambda x : x[0]+'_'+str(x[1]) if x[1]>0 else x[0], axis=1)
new_feature_name_df = new_feature_name_df.drop(['index'], axis=1)
return new_feature_name_df
In [ ]:
import pandas as pd
def get_human_dataset():
feature_name_df = pd.read_csv('features.txt', sep='\s+', header=None, names=['column_index', 'column_name'])
new_feature_name_df = get_new_feature_name_df(feature_name_df)
feature_name = new_feature_name_df.iloc[:, 1].values.tolist()
X_train = pd.read_csv('/content/X_train.txt', sep='\s+', names=feature_name)
X_test = pd.read_csv('/content/X_test.txt', sep='\s+', names=feature_name)
y_train = pd.read_csv('/content/y_train.txt', sep='\s+', header=None, names=['action'])
y_test = pd.read_csv('/content/y_test.txt', sep='\s+', header=None, names=['action'])
return X_train, X_test, y_train, y_test
X_train, X_test, y_train, y_test = get_human_dataset()
In [ ]:
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import accuracy_score
import time
import warnings
warnings.filterwarnings('ignore')
X_train, X_test, y_train, y_test = get_human_dataset()
start_time = time.time()
gb_clf = GradientBoostingClassifier(random_state=0)
gb_clf.fit(X_train, y_train)
pred = gb_clf.predict(X_test)
gb_accuracy = accuracy_score(y_test, pred)
print('GBM 정확도: {0:.4f}'.format(gb_accuracy))
print('GBM 수행 시간: {0:.1f}'.format(time.time() - start_time))
GBM 정확도: 0.9386
GBM 수행 시간: 959.2
- 기본 하이퍼 파라미터만으로 93.89%의 정확도로 앞의 랜덤포레스트보다 나은 성능을 보임
- 그러나 수행 시간이 오래 걸리고, 하이퍼 파라미터 튜닝 노력도 더 필요함
GBM 하이퍼 파라미터 소개
(트리 기반 자체의 파라미터는 제외하고)
- loss: 경사하강법에서 사용할 비용 함수를 지정함, 특별한 이유없으면 디폴트인 'deviance'를 그대로 적용
- learning_rate: GBM이 학습을 진행할 때마다 적용하는 학습률, 약한 학습기가 순차적으로 오류값을 보정해 나가는데에 적용하는 계수너무 작으면 업데이트되는 값이 작아져서 성능이 높아지지만 수행시간이 오래 걸리고 최소 오류값을 찾지 못할 수 있음따라서, n_estimators와 조합하여 상호 보완
- 너무 크면 최소 오류값을 찾지 못하고 그냥 지나쳐버려서 성능이 떨어질 수 있지만 빠른 수행 가능
- 0~1사이의 값, 디폴트는 0.1
- n_estimators: 약한 학습기의 개수, 개수가 많을수록 성능이 일정 수준까지는 좋아지지만 시간이 오래 걸림
- 디폴트는 100개
- subsample: 약한 학습기가 학습에 사용하는 데이터의 샘플링 비율, 디폴트는 1(전체 학습 데이터를 기반으로 학습한단 의미, 0.5면 50%)
- 과적합이 걱정되면 1보다 작게 설정
'Data Science > 파이썬 머신러닝 완벽 가이드' 카테고리의 다른 글
| [sklearn] (24) 사이킷런 Wrapper XGBoost (0) | 2023.05.30 |
|---|---|
| [sklearn] (23) - XGBoost (eXtra Gradient Boost) (0) | 2023.05.29 |
| [sklearn] (21) 사용자 행동 인식 예측 분류 - DecisionTreeClassifier (0) | 2023.05.25 |
| [sklearn] (20) 랜덤 포레스트 RandomForestClassifier (1) | 2023.05.24 |
| [sklearn] (19) 앙상블 기법 Ensemble, 위스콘신 유방암 데이터 - VotingClassifier(), load_breast_cancer() (0) | 2023.05.24 |