
성능 평가 지표
정확도(Accuracy)
- 정확도는 전체 예측 데이터 건수 중 예측 결과가 동일한 데이터 건수로 계산
- scikit-learn에서는
accuracy_score함수를 제공
In [60]:
from sklearn.datasets import make_classification
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
X, y = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
model = LogisticRegression()
model.fit(X_train, y_train)
print('훈련 데이터 점수: {}'.format(model.score(X_train, y_train)))
print('평가 데이터 점수: {}'.format(model.score(X_test, y_test)))
predict = model.predict(X_test)
print('정확도: {}'.format(accuracy_score(y_test, predict)))
훈련 데이터 점수: 0.9771428571428571
평가 데이터 점수: 0.9566666666666667
정확도: 0.9566666666666667
오차 행렬(Confusion Matrix)
- True Negative: 예측값을 Negative 값 0으로 예측했고, 실제 값도 Negative 값 0
- False Positive: 예측값을 Positive 값 1로 예측했는데, 실제 값은 Negative 값 0
- False Negative: 예측값을 Negative 값 0으로 예측했는데, 실제 값은 Positive 값 1
- True Positive: 예측값을 Positive 값 1로 예측했고, 실제 값도 Positive 값 1
In [62]:
from sklearn.metrics import confusion_matrix
confmat = confusion_matrix(y_true=y_test, y_pred=predict)
print(confmat)
[[159 7]
[ 6 128]]
In [69]:
fig, ax = plt.subplots(figsize=(2.5, 2.5))
ax.matshow(confmat, cmap=plt.cm.Blues, alpha=0.3)
for i in range(confmat.shape[0]):
for j in range(confmat.shape[1]):
ax.text(x=j, y=i, s=confmat[i, j], va='center', ha='center')
plt.xlabel('Predicted label')
plt.ylabel('True label')
plt.tight_layout()
plt.show()

- 0을 0이라고 예측한 결과 159개, TN
- 0을 1이라고 예측한 결과 7개, FP
- 1을 0이라고 예측한 결과 6개, FN
- 1을 1이라고 예측한 결과 128개, TP
정밀도(Precision)와 재현율(Recall)
- 정밀도 = TP / (FP + TP) >> 위의 예시에서 정밀도 값: 0.94814..
- 재현율 = TP / (FN + TP) >> 재현율 값: 0.95522...
- 정확도 = (TN + TP) / (TN + FP + FN + TP) >> 정확도 값: 0.95666...
- 오류율(1-정확도) = (FN + FP) / (TN + FP + FN + TP) >> 오류율: 0.0433.. >> 약 4.3%
In [71]:
from sklearn.metrics import precision_score, recall_score
precision = precision_score(y_test, predict)
recall = recall_score(y_test, predict)
print('정밀도: {}'.format(precision))
print('재현율: {}'.format(recall))
정밀도: 0.9481481481481482
재현율: 0.9552238805970149
F1 Score(F-measure)
- 정밀도와 재현율을 결합한 지표
- 정밀도와 재현율이 어느 한쪽으로 치우치지 않을 때 높은 값을 가짐
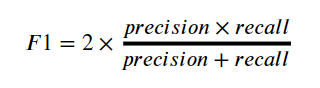
In [72]:
from sklearn.metrics import f1_score
f1 = f1_score(y_test, predict)
print('F1 Score: {}'.format(f1))
F1 Score: 0.9516728624535316
ROC 곡선과 AUC
- ROC 곡선은 FPR(False Positive Rate)이 변할 때 TPR(True Positive Rate)이 어떻게 변하는지 나타내는 곡선
- TPR(True Positive Rate): TP / (FN + TP), 재현율
- TNR(True Negative Rate): TN / (FP + TN)
- FPR(False Positive Rate): FP / (FP + TN), 1 - TNR
- AUC(Area Under Curve) 값은 ROC 곡선 밑에 면적을 구한 값 (1이 가까울수록 좋은 값)
In [74]:
import numpy as np
from sklearn.metrics import roc_curve
pred_proba_class1 = model.predict_proba(X_test)[:, 1]
fprs, tprs, thresholds = roc_curve(y_test, pred_proba_class1)
plt.plot(fprs, tprs, label='ROC')
plt.plot([0,1], [0,1], '--k', label='Random')
start, end = plt.xlim()
plt.xticks(np.round(np.arange(start, end, 0.1), 2))
plt.xlim(0,1)
plt.ylim(0,1)
plt.xlabel('FPR(1-Sensitivity)')
plt.ylabel('TPR(Recall)')
plt.legend()
Out[74]:
<matplotlib.legend.Legend at 0x1f026c26b90>

- 점선에 가까울수록 성능이 안좋은 것임
In [76]:
#AUC(Area Under Curve) 값은 ROC 곡선 밑에 면적을 구한 값 (1이 가까울수록 좋은 값)
from sklearn.metrics import roc_auc_score
roc_auc = roc_auc_score(y_test, predict)
print('ROC AUC Score: {}'.format(roc_auc))
ROC AUC Score: 0.95652760294911
출처, 참고자료: www.suanlab.com
Home | SuanLab
한국과 일본의 데이터베이스 연구자 분들이 정례적으로 진행하는 Korea-Japan Database (KJDB) 워크숍이 12월 2일(금)~3일(토)에 개최됩니다. 코로나-19로 인하여 작년과 마찬가지로 온라인으로 진행됩니
suanlab.com
'Data Science > 파이썬 머신러닝 완벽 가이드' 카테고리의 다른 글
| [sklearn] (4) iris 품종 분류 예측하기 (0) | 2023.04.30 |
|---|---|
| [Dacon] 보스턴 집값 예측 (0) | 2023.04.20 |
| [sklearn] (2) preprocessing 데이터 전처리 모듈 (0) | 2023.04.20 |
| [sklearn] (1) model_selection 모듈 (0) | 2023.04.20 |
| [sklearn] 사이킷런(scikit-learn) 시작하기 (0) | 2023.04.20 |
성능 평가 지표
정확도(Accuracy)
- 정확도는 전체 예측 데이터 건수 중 예측 결과가 동일한 데이터 건수로 계산
- scikit-learn에서는
accuracy_score함수를 제공
In [60]:
from sklearn.datasets import make_classification
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
X, y = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
model = LogisticRegression()
model.fit(X_train, y_train)
print('훈련 데이터 점수: {}'.format(model.score(X_train, y_train)))
print('평가 데이터 점수: {}'.format(model.score(X_test, y_test)))
predict = model.predict(X_test)
print('정확도: {}'.format(accuracy_score(y_test, predict)))
훈련 데이터 점수: 0.9771428571428571
평가 데이터 점수: 0.9566666666666667
정확도: 0.9566666666666667
오차 행렬(Confusion Matrix)
- True Negative: 예측값을 Negative 값 0으로 예측했고, 실제 값도 Negative 값 0
- False Positive: 예측값을 Positive 값 1로 예측했는데, 실제 값은 Negative 값 0
- False Negative: 예측값을 Negative 값 0으로 예측했는데, 실제 값은 Positive 값 1
- True Positive: 예측값을 Positive 값 1로 예측했고, 실제 값도 Positive 값 1
In [62]:
from sklearn.metrics import confusion_matrix
confmat = confusion_matrix(y_true=y_test, y_pred=predict)
print(confmat)
[[159 7]
[ 6 128]]
In [69]:
fig, ax = plt.subplots(figsize=(2.5, 2.5))
ax.matshow(confmat, cmap=plt.cm.Blues, alpha=0.3)
for i in range(confmat.shape[0]):
for j in range(confmat.shape[1]):
ax.text(x=j, y=i, s=confmat[i, j], va='center', ha='center')
plt.xlabel('Predicted label')
plt.ylabel('True label')
plt.tight_layout()
plt.show()
- 0을 0이라고 예측한 결과 159개, TN
- 0을 1이라고 예측한 결과 7개, FP
- 1을 0이라고 예측한 결과 6개, FN
- 1을 1이라고 예측한 결과 128개, TP
정밀도(Precision)와 재현율(Recall)
- 정밀도 = TP / (FP + TP) >> 위의 예시에서 정밀도 값: 0.94814..
- 재현율 = TP / (FN + TP) >> 재현율 값: 0.95522...
- 정확도 = (TN + TP) / (TN + FP + FN + TP) >> 정확도 값: 0.95666...
- 오류율(1-정확도) = (FN + FP) / (TN + FP + FN + TP) >> 오류율: 0.0433.. >> 약 4.3%
In [71]:
from sklearn.metrics import precision_score, recall_score
precision = precision_score(y_test, predict)
recall = recall_score(y_test, predict)
print('정밀도: {}'.format(precision))
print('재현율: {}'.format(recall))
정밀도: 0.9481481481481482
재현율: 0.9552238805970149
F1 Score(F-measure)
- 정밀도와 재현율을 결합한 지표
- 정밀도와 재현율이 어느 한쪽으로 치우치지 않을 때 높은 값을 가짐
In [72]:
from sklearn.metrics import f1_score
f1 = f1_score(y_test, predict)
print('F1 Score: {}'.format(f1))
F1 Score: 0.9516728624535316
ROC 곡선과 AUC
- ROC 곡선은 FPR(False Positive Rate)이 변할 때 TPR(True Positive Rate)이 어떻게 변하는지 나타내는 곡선
- TPR(True Positive Rate): TP / (FN + TP), 재현율
- TNR(True Negative Rate): TN / (FP + TN)
- FPR(False Positive Rate): FP / (FP + TN), 1 - TNR
- AUC(Area Under Curve) 값은 ROC 곡선 밑에 면적을 구한 값 (1이 가까울수록 좋은 값)
In [74]:
import numpy as np
from sklearn.metrics import roc_curve
pred_proba_class1 = model.predict_proba(X_test)[:, 1]
fprs, tprs, thresholds = roc_curve(y_test, pred_proba_class1)
plt.plot(fprs, tprs, label='ROC')
plt.plot([0,1], [0,1], '--k', label='Random')
start, end = plt.xlim()
plt.xticks(np.round(np.arange(start, end, 0.1), 2))
plt.xlim(0,1)
plt.ylim(0,1)
plt.xlabel('FPR(1-Sensitivity)')
plt.ylabel('TPR(Recall)')
plt.legend()
Out[74]:
<matplotlib.legend.Legend at 0x1f026c26b90>
- 점선에 가까울수록 성능이 안좋은 것임
In [76]:
#AUC(Area Under Curve) 값은 ROC 곡선 밑에 면적을 구한 값 (1이 가까울수록 좋은 값)
from sklearn.metrics import roc_auc_score
roc_auc = roc_auc_score(y_test, predict)
print('ROC AUC Score: {}'.format(roc_auc))
ROC AUC Score: 0.95652760294911
출처, 참고자료: www.suanlab.com
Home | SuanLab
한국과 일본의 데이터베이스 연구자 분들이 정례적으로 진행하는 Korea-Japan Database (KJDB) 워크숍이 12월 2일(금)~3일(토)에 개최됩니다. 코로나-19로 인하여 작년과 마찬가지로 온라인으로 진행됩니
suanlab.com
'Data Science > 파이썬 머신러닝 완벽 가이드' 카테고리의 다른 글
| [sklearn] (4) iris 품종 분류 예측하기 (0) | 2023.04.30 |
|---|---|
| [Dacon] 보스턴 집값 예측 (0) | 2023.04.20 |
| [sklearn] (2) preprocessing 데이터 전처리 모듈 (0) | 2023.04.20 |
| [sklearn] (1) model_selection 모듈 (0) | 2023.04.20 |
| [sklearn] 사이킷런(scikit-learn) 시작하기 (0) | 2023.04.20 |