Data Science/파이썬 머신러닝 완벽 가이드
[sklearn] (1) model_selection 모듈
얆생
2023. 4. 20. 01:10
model_selection 모듈
- 학습용 데이터와 테스트 데이터로 분리
- 교차 검증 분할 및 평가
- Estimator의 하이퍼 파라미터 튜닝을 위한 다양한 함수와 클래스 제공
train_test_split(): 학습/테스트 데이터 세트 분리
In [32]:
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_diabetes
diabetes = load_diabetes()
X_train, X_test, y_train, y_test = train_test_split(diabetes.data, diabetes.target, test_size=0.3)
#여러개의 feature들이 나오기 때문에 대문자 X로 표현, 훈련용 데이터가 30퍼센트
model = LinearRegression()
model.fit(X_train, y_train)
print('학습데이터 점수: {}'.format(model.score(X_train, y_train)))
print('평가데이터 점수: {}'.format(model.score(X_test, y_test)))
학습데이터 점수: 0.5137508183555365
평가데이터 점수: 0.497365877255851
In [35]:
import matplotlib.pyplot as plt
predicted = model.predict(X_test)
expected = y_test
plt.figure(figsize=(8, 4))
plt.scatter(expected, predicted)
plt.plot([30, 350], [30, 350], '--r')
plt.tight_layout()

- 빨간선에 가까울 수록 잘 맞춘건데 정확도가 높지 않음
cross_val_score(): 교차 검증
In [37]:
from sklearn.model_selection import cross_val_score, cross_validate
scores = cross_val_score(model, diabetes.data, diabetes.target, cv=5)
print('교차 검증 정확도: {}'.format(scores))
print('교차 검증 정확도: {} +/- {}'.format(np.mean(scores), np.std(scores)))
교차 검증 정확도: [0.42955615 0.52259939 0.48268054 0.42649776 0.55024834]
교차 검증 정확도: 0.48231643590864215 +/- 0.04926857751190387
GridSearchCV: 교차 검증과 최적 하이퍼 파라미터 찾기
- 훈련 단계에서 학습한 파라미터에 영향을 받아서 최상의 파라미터를 찾는 일은 항상 어려운 문제
- 다양한 모델의 훈련 과정을 자동화하고, 교차 검사를 사용해 최적 값을 제공하는 도구 필요
from sklearn.model_selection import GridSearchCV
from sklearn.linear_model import Ridge
import pandas as pd
alpha = [0.001, 0.01, 0.1, 1, 10, 100, 1000]
param_grid = dict(alpha=alpha)
gs = GridSearchCV(estimator=Ridge(), param_grid=param_grid, cv=10)
results = gs.fit(diabetes.data, diabetes.target)
print('최적 점수: {}'.format(results.best_score_))
print('최적 파라미터: {}'.format(results.best_params_))
print(gs.best_estimator_)
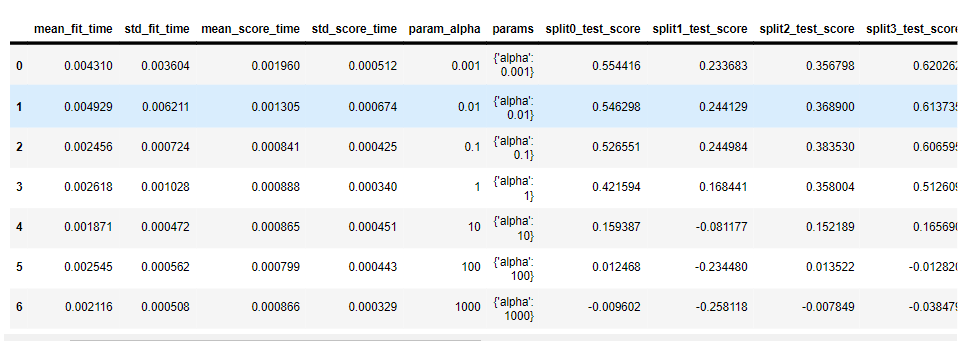
pd.DataFrame(results.cv_results_)최적 점수: 0.46332219117960366
최적 파라미터: {'alpha': 0.1}
Ridge(alpha=0.1)
multiprocessing을 이용한 GridSearchCV
import multiprocessing
from sklearn.datasets import load_iris
from sklearn.linear_model import LogisticRegression
iris = load_iris()
param_grid = [ {'penalty': ['l1', 'l2'], 'C': [1.5, 2.0, 2.5, 3.0, 3.5] } ]
gs = GridSearchCV(estimator=LogisticRegression(), param_grid=param_grid, scoring='accuracy', cv=10, n_jobs=multiprocessing.cpu_count())
result = gs.fit(iris.data, iris.target)
print('최적 점수: {}'.format(results.best_score_))
print('최적 파라미터: {}'.format(results.best_params_))
print(gs.best_estimator_)
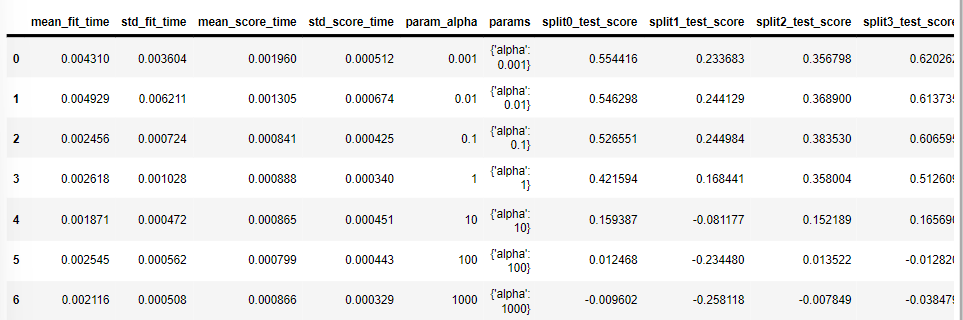
pd.DataFrame(results.cv_results_)최적 점수: 0.46332219117960366
최적 파라미터: {'alpha': 0.1}
LogisticRegressoin(C=2.5)
참고자료, 출처: www.suanlab.com
Home | SuanLab
한국과 일본의 데이터베이스 연구자 분들이 정례적으로 진행하는 Korea-Japan Database (KJDB) 워크숍이 12월 2일(금)~3일(토)에 개최됩니다. 코로나-19로 인하여 작년과 마찬가지로 온라인으로 진행됩니
suanlab.com