[sklearn] 사이킷런(scikit-learn) 시작하기

scikit-learn 특징
- 다양한 머신러닝 알고리즘을 구현한 파이썬 라이브러리
- 심플하고 일관성 있는 API, 유용한 온라인 문서, 풍부한 예제
- 머신러닝을 위한 쉽고 효율적인 개발 라이브러리 제공
- 다양한 머신러닝 관련 알고리즘과 개발을 위한 프레임워크와 API 제공
- 많은 사람들이 사용하며 다양한 환경에서 검증된 라이브러리
scikit-learn 주요 모듈
| sklearn.datasets | 내장된 예제 데이터 세트 |
| sklearn.preprocessing | 다양한 데이터 전처리 기능 제공 (변환, 정규화, 스케일링 등) |
| sklearn.feature_selection | 특징(feature)를 선택할 수 있는 기능 제공 |
| sklearn.feature_extraction | 특징(feature) 추출에 사용 |
| sklearn.decomposition | 차원 축소 관련 알고리즘 지원 (PCA, NMF, Truncated SVD 등) |
| sklearn.model_selection | 교차 검증을 위해 데이터를 학습/테스트용으로 분리, 최적 파라미터를 추출하는 API 제공 (GridSearch 등) |
| sklearn.metrics | 분류, 회귀, 클러스터링, Pairwise에 대한 다양한 성능 측정 방법 제공 (Accuracy, Precision, Recall, ROC-AUC, RMSE 등) |
| sklearn.pipeline | 특징 처리 등의 변환과 ML 알고리즘 학습, 예측 등을 묶어서 실행할 수 있는 유틸리티 제공 |
| sklearn.linear_model | 선형 회귀, 릿지(Ridge), 라쏘(Lasso), 로지스틱 회귀 등 회귀 관련 알고리즘과 SGD(Stochastic Gradient Descent) 알고리즘 제공 |
| sklearn.svm | 서포트 벡터 머신 알고리즘 제공 |
| sklearn.neighbors | 최근접 이웃 알고리즘 제공 (k-NN 등) |
| sklearn.naive_bayes | 나이브 베이즈 알고리즘 제공 (가우시안 NB, 다항 분포 NB 등) |
| sklearn.tree | 의사 결정 트리 알고리즘 제공 |
| sklearn.ensemble | 앙상블 알고리즘 제공 (Random Forest, AdaBoost, GradientBoost 등) |
| sklearn.cluster | 비지도 클러스터링 알고리즘 제공 (k-Means, 계층형 클러스터링, DBSCAN 등) |
estimator API
- 일관성: 모든 객체는 일관된 문서를 갖춘 제한된 메서드 집합에서 비롯된 공통 인터페이스 공유
- 검사(inspection): 모든 지정된 파라미터 값은 공개 속성으로 노출
- 제한된 객체 계층 구조
- 알고리즘만 파이썬 클래스에 의해 표현
- 데이터 세트는 표준 포맷(NumPy 배열, Pandas DataFrame, Scipy 희소 행렬)으로 표현
- 매개변수명은 표준 파이썬 문자열 사용
- 구성: 많은 머신러닝 작업은 기본 알고리즘의 시퀀스로 나타낼 수 있으며, Scikit-Learn은 가능한 곳이라면 어디서든 이 방식을 사용
- 합리적인 기본값: 모델이 사용자 지정 파라미터를 필요로 할 때 라이브러리가 적절한 기본값을 정의
API 사용 방법
- Scikit-Learn으로부터 적절한 estimator 클래스를 임포트해서 모델의 클래스 선택
- 클래스를 원하는 값으로 인스턴스화해서 모델의 하이퍼파라미터 선택
- 데이터를 특징 배열과 대상 벡터로 배치
- 모델 인스턴스의 fit() 메서드를 호출해 모델을 데이터에 적합
- 모델을 새 데이터에 대해서 적용
- 지도 학습: 대체로 predict() 메서드를 사용해 알려지지 않은 데이터에 대한 레이블 예측
- 비지도 학습: 대체로 transform()이나 predict() 메서드를 사용해 데이터의 속성을 변환하거나 추론
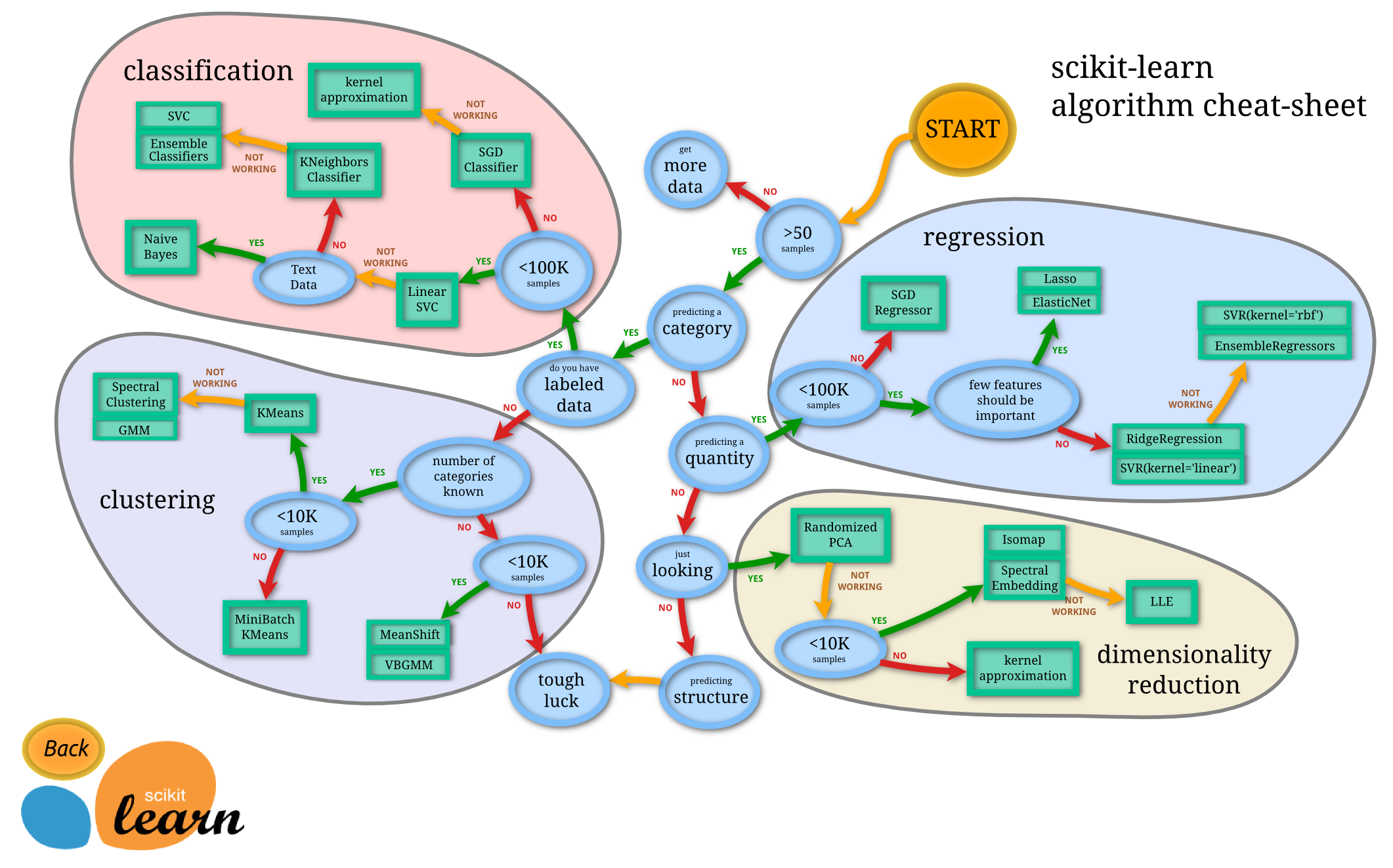
API 사용 예제
import numpy as np
import matplotlib.pyplot as plt
plt.style.use(['seaborn-whitegrid'])
C:\Users\Administrator\AppData\Local\Temp\ipykernel_2392\122571495.py:3: MatplotlibDeprecationWarning: The seaborn styles shipped by Matplotlib are deprecated since 3.6, as they no longer correspond to the styles shipped by seaborn. However, they will remain available as 'seaborn-v0_8-<style>'. Alternatively, directly use the seaborn API instead.
plt.style.use(['seaborn-whitegrid'])
x = 10 * np.random.rand(50)
y = 2 * x + np.random.rand(50)
plt.scatter(x, y);
Out[3]:
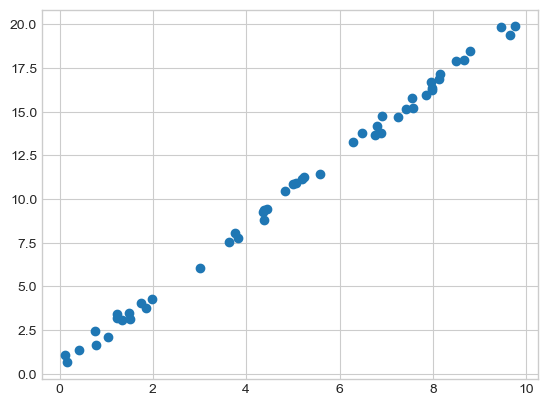
# 1. 적절한 estimator 클래스를 임포트해서 모델의 클래스 선택
from sklearn.linear_model import LinearRegression
# 2. 클래스를 원하는 값으로 인스턴스화해서 모델의 하이퍼파라미터 선택
model = LinearRegression(fit_intercept=True)
model
# 3. 데이터를 특징 배열과 대상 벡터로 배치
X = x[:, np.newaxis] #특징 배열로 만듬, 2차원
X
Out[7]:
array([[9.76879152],
[1.23049839],
[1.49080163],
[7.25312468],
[8.48967739],
[5.23801105],
[8.15707778],
[3.81781457],
[3.00543595],
[7.54874611],
[5.58592269],
[6.76616069],
[8.66300103],
[7.57497027],
[1.97729369],
[3.75282954],
[1.33855232],
[0.10618142],
[6.49101653],
[0.74986447],
[7.97353774],
[7.4338429 ],
[4.37004295],
[3.62705869],
[0.14850336],
[7.98137034],
[0.78607912],
[4.45501996],
[6.88705609],
[9.46750613],
[1.22530673],
[6.91009708],
[9.66026969],
[8.79294101],
[4.8312291 ],
[1.84163185],
[5.005855 ],
[6.28940354],
[1.74540839],
[4.38714726],
[7.95206735],
[1.51738087],
[7.84460097],
[5.05982438],
[5.20482028],
[0.41025632],
[1.04191342],
[8.13231794],
[6.81192182],
[4.36818344]])
# 4. 모델 인스턴스의 fit() 메서드를 호출해 모델을 데이터에 적합
model.fit(X, y)
LinearRegression()model.coef_ #model에서 return 시켜주는 parameter들이 있음
Out[9]: array([2.01050962])
model.intercept_
Out[10]: 0.43794995811682114
# 5. 모델을 새 데이터에 대해서 적용
xfit = np.linspace(-1, 11)
Xfit = xfit[:, np.newaxis]
yfit = model.predict(Xfit)
plt.scatter(x, y)
plt.plot(xfit, yfit, '--r')
Out[15]: [<matplotlib.lines.Line2D at 0x22c04a2b160>]
예제 데이터 세트
분류 또는 회귀용 데이터 세트
API설명| datasets.load_boston() | 미국 보스턴의 집에 대한 특징과 가격 데이터 (회귀용) |
| datasets.load_breast_cancer() | 위스콘신 유방암 특징들과 악성/음성 레이블 데이터 (분류용) |
| datasets.load_diabetes() | 당뇨 데이터 (회귀용) |
| datasets.load_digits() | 0에서 9까지 숫자 이미지 픽셀 데이터 (분류용) |
| datasets.load_iris() | 붓꽃에 대한 특징을 가진 데이터 (분류용) |
온라인 데이터 세트
- 데이터 크기가 커서 온라인에서 데이터를 다운로드 한 후에 불러오는 예제 데이터 세트
| fetch_california_housing() | 캘리포니아 주택 가격 데이터 |
| fetch_covtype() | 회귀 분석용 토지 조사 데이터 |
| fetch_20newsgroups() | 뉴스 그룹 텍스트 데이터 |
| fetch_olivetti_faces() | 얼굴 이미지 데이터 |
| fetch_lfw_people() | 얼굴 이미지 데이터 |
| fetch_lfw_paris() | 얼굴 이미지 데이터 |
| fetch_rcv1() | 로이터 뉴스 말뭉치 데이터 |
| fetch_mldata() | ML 웹사이트에서 다운로드 |
분류와 클러스터링을 위한 표본 데이터 생성
| datasets.make_classifications() | 분류를 위한 데이터 세트 생성. 높은 상관도, 불필요한 속성 등의 노이즈를 고려한 데이터를 무작위로 생성 |
| datasets.make_blobs() | 클러스터링을 위한 데이터 세트 생성. 군집 지정 개수에 따라 여러 가지 클러스터링을 위한 데이터 셋트를 무작위로 생성 |
예제 데이터 세트 구조
- 일반적으로 딕셔너리 형태로 구성
- data: 특징 데이터 세트
- target: 분류용은 레이블 값, 회귀용은 숫자 결과값 데이터
- target_names: 개별 레이블의 이름 (분류용)
- feature_names: 특징 이름
- DESCR: 데이터 세트에 대한 설명과 각 특징 설명
from sklearn.datasets import load_diabetes
diabetes = load_diabetes()
print(diabetes.keys())
Out[18]: dict_keys(['data', 'target', 'frame', 'DESCR', 'feature_names', 'data_filename', 'target_filename', 'data_module'])
print(diabetes.data)
Out[19]:
[[ 0.03807591 0.05068012 0.06169621 ... -0.00259226 0.01990749
-0.01764613]
[-0.00188202 -0.04464164 -0.05147406 ... -0.03949338 -0.06833155
-0.09220405]
[ 0.08529891 0.05068012 0.04445121 ... -0.00259226 0.00286131
-0.02593034]
...
[ 0.04170844 0.05068012 -0.01590626 ... -0.01107952 -0.04688253
0.01549073]
[-0.04547248 -0.04464164 0.03906215 ... 0.02655962 0.04452873
-0.02593034]
[-0.04547248 -0.04464164 -0.0730303 ... -0.03949338 -0.00422151
0.00306441]]
print(diabetes.target)
Out[21]:
[151. 75. 141. 206. 135. 97. 138. 63. 110. 310. 101. 69. 179. 185.
118. 171. 166. 144. 97. 168. 68. 49. 68. 245. 184. 202. 137. 85.
131. 283. 129. 59. 341. 87. 65. 102. 265. 276. 252. 90. 100. 55.
61. 92. 259. 53. 190. 142. 75. 142. 155. 225. 59. 104. 182. 128.
52. 37. 170. 170. 61. 144. 52. 128. 71. 163. 150. 97. 160. 178.
48. 270. 202. 111. 85. 42. 170. 200. 252. 113. 143. 51. 52. 210.
65. 141. 55. 134. 42. 111. 98. 164. 48. 96. 90. 162. 150. 279.
92. 83. 128. 102. 302. 198. 95. 53. 134. 144. 232. 81. 104. 59.
246. 297. 258. 229. 275. 281. 179. 200. 200. 173. 180. 84. 121. 161.
99. 109. 115. 268. 274. 158. 107. 83. 103. 272. 85. 280. 336. 281.
118. 317. 235. 60. 174. 259. 178. 128. 96. 126. 288. 88. 292. 71.
197. 186. 25. 84. 96. 195. 53. 217. 172. 131. 214. 59. 70. 220.
268. 152. 47. 74. 295. 101. 151. 127. 237. 225. 81. 151. 107. 64.
138. 185. 265. 101. 137. 143. 141. 79. 292. 178. 91. 116. 86. 122.
72. 129. 142. 90. 158. 39. 196. 222. 277. 99. 196. 202. 155. 77.
191. 70. 73. 49. 65. 263. 248. 296. 214. 185. 78. 93. 252. 150.
77. 208. 77. 108. 160. 53. 220. 154. 259. 90. 246. 124. 67. 72.
257. 262. 275. 177. 71. 47. 187. 125. 78. 51. 258. 215. 303. 243.
91. 150. 310. 153. 346. 63. 89. 50. 39. 103. 308. 116. 145. 74.
45. 115. 264. 87. 202. 127. 182. 241. 66. 94. 283. 64. 102. 200.
265. 94. 230. 181. 156. 233. 60. 219. 80. 68. 332. 248. 84. 200.
55. 85. 89. 31. 129. 83. 275. 65. 198. 236. 253. 124. 44. 172.
114. 142. 109. 180. 144. 163. 147. 97. 220. 190. 109. 191. 122. 230.
242. 248. 249. 192. 131. 237. 78. 135. 244. 199. 270. 164. 72. 96.
306. 91. 214. 95. 216. 263. 178. 113. 200. 139. 139. 88. 148. 88.
243. 71. 77. 109. 272. 60. 54. 221. 90. 311. 281. 182. 321. 58.
262. 206. 233. 242. 123. 167. 63. 197. 71. 168. 140. 217. 121. 235.
245. 40. 52. 104. 132. 88. 69. 219. 72. 201. 110. 51. 277. 63.
118. 69. 273. 258. 43. 198. 242. 232. 175. 93. 168. 275. 293. 281.
72. 140. 189. 181. 209. 136. 261. 113. 131. 174. 257. 55. 84. 42.
146. 212. 233. 91. 111. 152. 120. 67. 310. 94. 183. 66. 173. 72.
49. 64. 48. 178. 104. 132. 220. 57.]
print(diabetes.DESCR)
print(diabetes.feature_names)
Out[24]: ['age', 'sex', 'bmi', 'bp', 's1', 's2', 's3', 's4', 's5', 's6']
print(diabetes.data_filename)
print(diabetes.target_filename)
Out[25]: diabetes_data_raw.csv.gz
diabetes_target.csv.gz
참고자료, 출처: www.suanlab.com
Home | SuanLab
한국과 일본의 데이터베이스 연구자 분들이 정례적으로 진행하는 Korea-Japan Database (KJDB) 워크숍이 12월 2일(금)~3일(토)에 개최됩니다. 코로나-19로 인하여 작년과 마찬가지로 온라인으로 진행됩니
suanlab.com